🪣 Cloud Data Access#
NASA’s migration from “on-premise” to cloud#
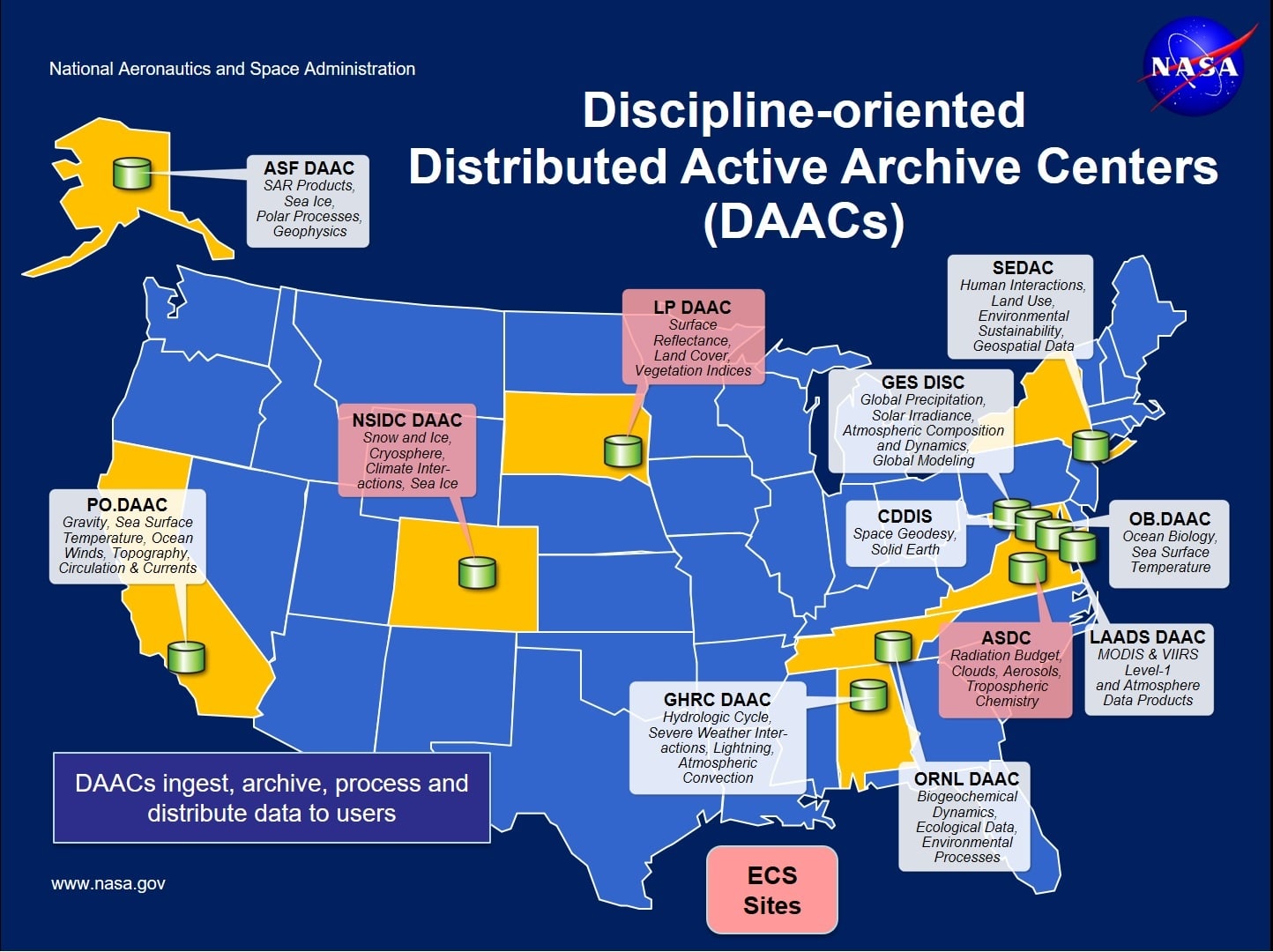
image src: https://asf.alaska.edu/about-asf-daac/
NASA has 12 Distributed Active Archive Centers (DAACs). Each DAAC is associated with a few sub-disciplines of Earth science, and those specialties correspond to which missions and data products those DAACs are in charge of. For example, LPDAAC is the land processes DAAC and is in charge of the Harmonized Landsat Sentinel (HLS) Product which is often used for land classification. Up until about 6 years ago (which is about when I started working with NASA), all NASA Earth Observation archives resided “on-premise” at the data center’s physical locations in data centers they manage.
NASA, anticipating the exponential growth in their Earth Observation data archives, started the Earthdata Cloud initiative. Now, NASA DAACs are in the process of migrating their collections to cloud storage. Existing missions are growing their collections as well, but new missions such as NISAR and SWOT are or will be the most significant contributors to NASA’s archival volume growth.
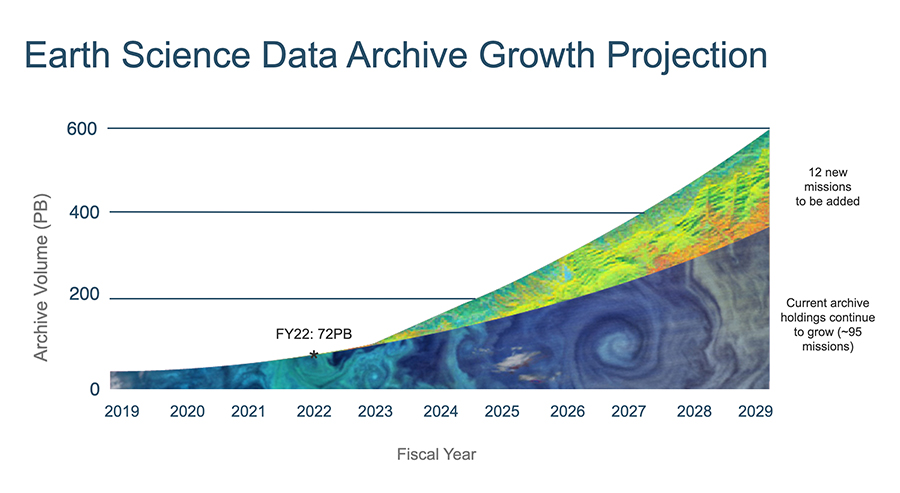
image src: https://www.earthdata.nasa.gov/esds/esds-highlights/2022-esds-highlights
Now, high priority and new datasets are being stored on cloud object storage.
What is cloud object storage?#
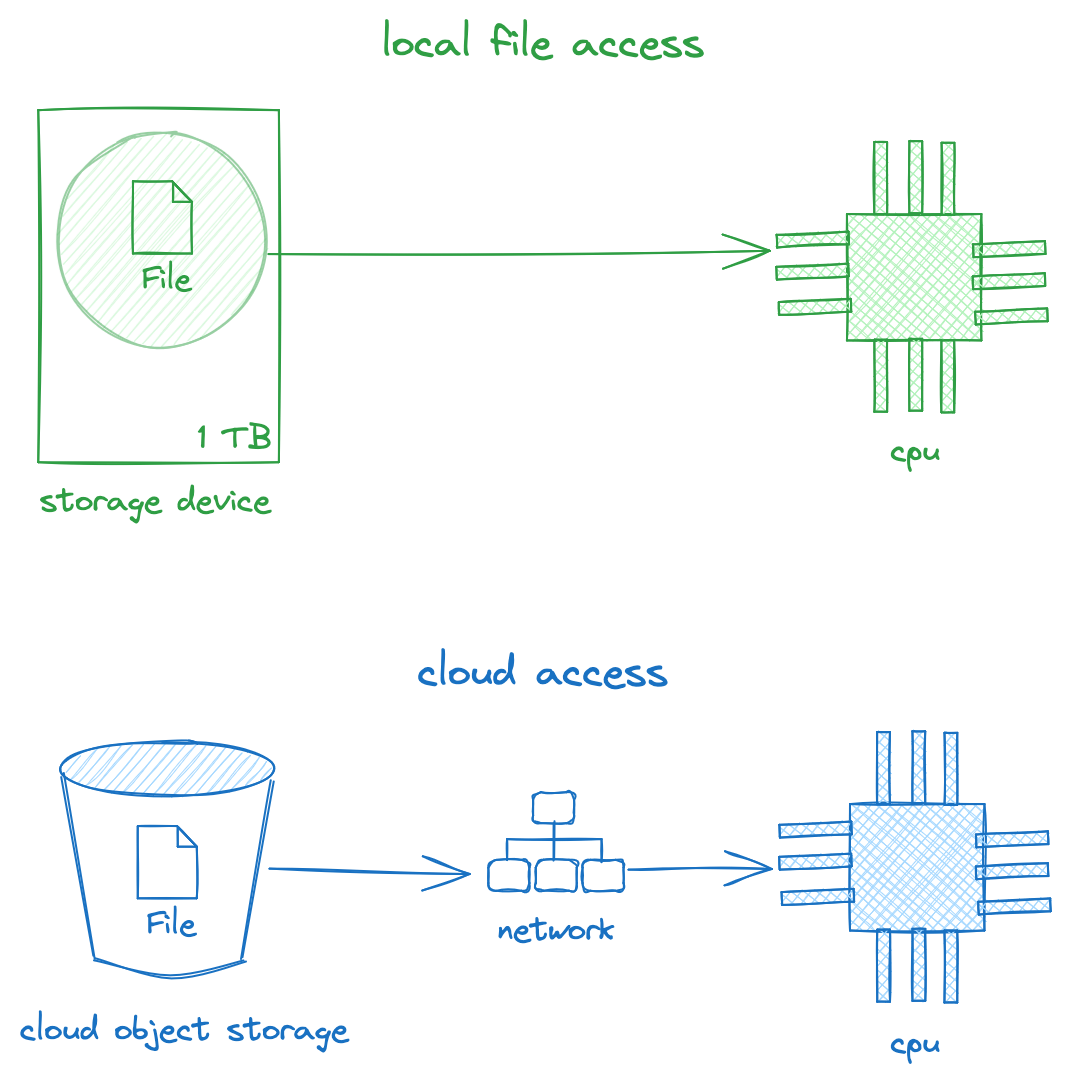
Cloud object storage stores unstructured data in a flat structure, called a bucket in AWS, where each object is identified with a unique key. The simple design of cloud object storage enables near infinite scalability. Object storage is distinguished from a database which requires database management system software to store data and often has connection limits. Object storage is distinct from file storage because files are stored in a hierarchical format and a network is not always required. Read more about cloud object storage and how it is different from other types of storage in the AWS docs.

Cloud object storage is accessible over the internet. If the data is public, you can use an HTTP link to access data in cloud object storage, but more typically you will use the cloud object storage protocol, such as s3://path/to/file.text along with some credentials to access the data. Using the s3 protocol to access the data is commonly referred to as direct access. Access over the network is critical because it means many servers can access data in parallel and these storage systems are designed to be infinitely scalable and always available.
Popular libraries to access data on S3 are boto3 and s3fs.
🏋️♀️ Exercise: Which ICESat-2 Datasets are on Earthdata Cloud?
Navigate https://search.earthdata.nasa.gov, search for ICESat-2 and answer the following questions:
How many ICESat-2 datasets are hosted on the AWS Cloud and how can you tell?
Which DAAC hosts ICESat-2 datasets?
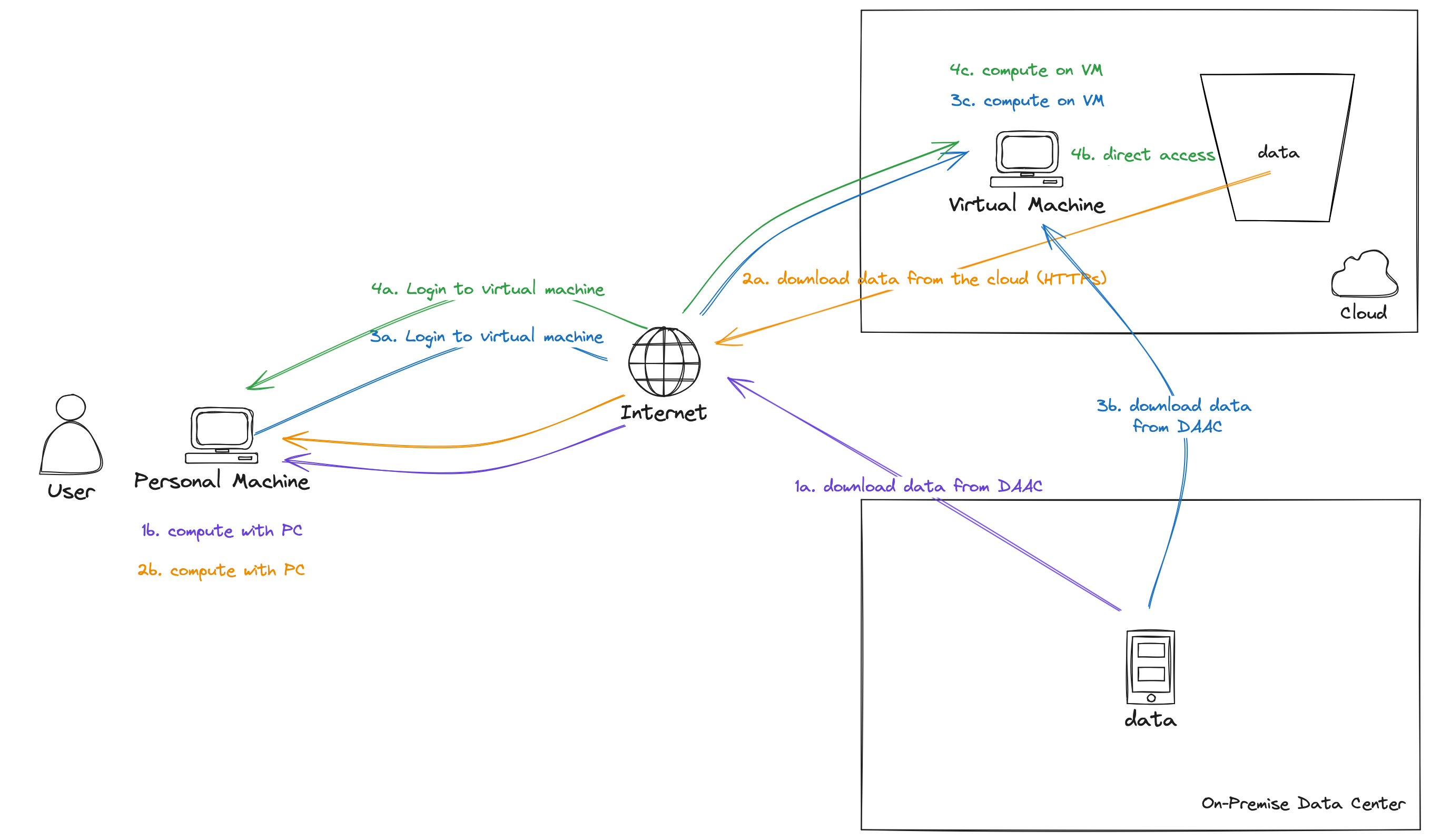
There are different access patterns, it can be confusing! 🤯#
Download data from a DAAC to your personal machine.
Download data from cloud storage, say using HTTP, to your personal machine.
Login to a virtual machine in the cloud, like CryoCloud, and download data from a DAAC.
Login to a virtual machine in the cloud and access data directly using a cloud object protocol, like s3.
🤔 Which should you chose and why?
You should use option 4: direct access. This is both because it is fastest overall and because of $$. You can download files stored in an S3 bucket using HTTPS, but this is not recommended. It is slow and, more importantly, egress - files being download outside of AWS services - is not free. For data on Earthdata Cloud, you can use S3 direct access if you are in the same AWS region as the data. This is so NASA can avoid egress fees 💸 but it also benefits you because this style of access is much faster. The good news is that CryoCloud is located in AWS us-west-2, the same region as NASA’s Earthdata Cloud datasets!
Caveats:
Not all datasets are on Earthdata cloud, so you may still need to access datasets from on-prem servers as well.
Having local file system access will always be faster than reading all or part of a file over a network, even in region (although S3 access is getting blazingly fast!) But you have to download the data, which is slow. You can also download objects from object storage onto a file system mounted onto a virtual machine, which would result in the fastest access and computation. But before architecting your applications this way, consider the tradeoffs of reproducibility (e.g. you’ll have to move the data ever time), cost (e.g. storage volumes can be more expensive than object storage) and scale (e.g. there is usually a volume size limit, except in the case of AWS Elastic File System which is even more pricey!).
🏋️♀️ Bonus Exercise: Comparing time to copy data from S3 to CryoCloud with time to download over HTTP to your personal machine
Note: You will need URS credentials handy to do this exercise. You will need to store them in a local ~/.netrc file as instructed here
earthaccess.login()
aws_creds = earthaccess.get_s3_credentials(daac='NSIDC')
s3 = s3fs.S3FileSystem(
key=aws_creds['accessKeyId'],
secret=aws_creds['secretAccessKey'],
token=aws_creds['sessionToken'],
)
results = earthaccess.search_data(
short_name="ATL03",
cloud_hosted=True,
count=1
)
direct_link = results[0].data_links(access="direct")[0]
direct_link
Now time the download:
%%time
s3.download(direct_link, lpath=direct_link.split('/')[-1])
Compare this with the time to download from HTTPS to your personal machine.
First, get the equivalent HTTPS URL:
http_link = results[0].data_links()[0]
http_link
Then, copy and paste the following into a shell prompt, replacing http_link with the string from the last command. You will need to follow the instructions here for this to work!
$ time curl -O -b ~/.urs_cookies -c ~/.urs_cookies -L -n {http_link}
For me, the first option, direct, in-region access took 11.1 seconds and HTTPS to personal machine took 1 minute and 48 seconds. The second value will depend on your wifi network.
Cloud vs Local Storage#
Feature |
Local |
Cloud |
|---|---|---|
Scalability |
❌ limited by physical hardware |
✅ highly scalable |
Accessibility |
❌ access is limited to local network or complex setup for remote access |
✅ accessible from anywhere with an internet connection |
Collaboration |
❌ sharing is hard |
✅ sharing is possible with tools for access control |
Data backup |
❌ risk of data loss due to hardware failure or human error |
✅ typically includes redundancy (read more) |
Performance |
✅ faster since it does not depend on any network |
❌ performance depends on internet speed or proximity to the data |
Takeaways
NASA datasets are still managed by DAACs, even though many datasets are moving to the cloud.
Users are encouraged to access the data directly in the cloud through AWS services (like cryocloud!)